
Vsebina

Vir: Kran77 / Dreamstime.com
Odvzem:
Modeli globinskega učenja učijo računalnike, da razmišljajo sami, z nekaj zelo zabavnimi in zanimivimi rezultati.
Globoko učenje se uporablja na vedno več področjih in panogah. Od avtomobilov brez voznikov, igranja Go, ustvarjanja glasbe za slike, vsak dan izhajajo novi modeli globokega učenja. Tu bomo preučili več priljubljenih modelov globokega učenja. Znanstveniki in razvijalci sprejemajo te modele in jih spreminjajo na nove in ustvarjalne načine. Upamo, da vas bo ta vitrina lahko navdihnila, da vidite, kaj je mogoče. (Če želite izvedeti o napredku umetne inteligence, glejte, ali bodo računalniki zmožni posnemati človeški možgan?)
Nevronski slog
Ne morete izboljšati svojih programskih veščin, kadar nikogar ne skrbi za kakovost programske opreme.
Nevronski pripovedovalec

Neural Storyteller je model, ki ob podobi lahko ustvari romantično zgodbo o sliki. Njegova zabavna igrača in kljub temu si lahko predstavljate prihodnost in vidite smer, v kateri se gibljejo vsi ti modeli umetne inteligence.

Zgornja funkcija je operacija "premik sloga", ki omogoča, da model prenaša standardne napise v slog zgodb iz romanov. Spreminjanje sloga je navdihnilo "Nevronski algoritem umetniškega sloga."
Podatki
V tem modelu sta dva glavna vira podatkov. MSCOCO je Microsoftov nabor podatkov, ki vsebuje približno 300.000 slik, pri čemer vsaka slika vsebuje pet napisov. MSCOCO je edini uporabljeni nadzorovani podatek, kar pomeni, da so to edini podatki, kamor so morali ljudje vstopiti in izrecno napisati napise za vsako sliko.
Ena od glavnih omejitev nevronske mreže, ki vodi naprej, je ta, da nima spomina. Vsaka napoved je neodvisna od prejšnjih izračunov, kot da bi bila prva in edina napoved, ki jo je omrežje kdajkoli storilo. Toda za številne naloge, na primer prevajanje stavka ali odstavka, morajo biti vnosi sestavljeni iz zaporednih in medsebojno povezanih podatkov. Na primer, težko bi bilo smiselno zabeležiti eno besedo v stavku, ne da bi ji zagotovili okoliške besede.
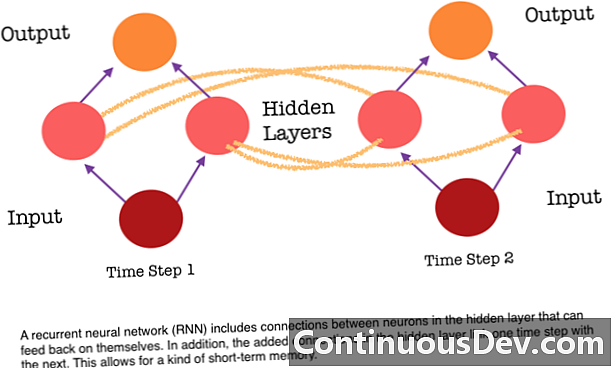
RNN so različni, ker dodajo drug sklop povezav med nevroni. Te povezave omogočajo, da se aktivacije nevronov v skriti plasti povrnejo vase na naslednjem koraku v zaporedju. Z drugimi besedami, skrit sloj prejme tako aktivacijo iz plasti pod njim kot tudi iz prejšnjega koraka v zaporedju. Ta struktura v bistvu daje pomnilnik ponavljajočih se nevronskih mrež. Torej, za nalogo odkrivanja predmetov lahko RNN nariše svoje prejšnje klasifikacije psov in tako pomaga ugotoviti, ali je trenutna slika pes.
Char-RNN TED
Ta prilagodljiva struktura v skriti plasti omogoča, da so RNN zelo dobri za jezikovne modele na ravni znakov. Char RNN, ki ga je prvotno ustvaril Andrej Karpathy, je model, ki vzame eno datoteko kot vhod in trenira RNN, da se nauči predvideti naslednji znak v zaporedju. RNN lahko ustvari znak po karakterju, ki bo podoben prvotnim podatkom vadbe. Demo je bil usposobljen z uporabo prepisov različnih TED pogovorov. Vnesite model eno ali več ključnih besed in ustvaril bo odlomek o ključnih besedah v glasu / slogu TED Talk.
Zaključek
Ti modeli prikazujejo nove preboje v strojni inteligenci, ki so postali možni zaradi globokega učenja. Globoko učenje kaže, da lahko rešimo težave, ki jih prej nikoli nismo mogli rešiti, in še nismo dosegli te planote. Pričakujte, da boste v naslednjih nekaj letih videli veliko bolj vznemirljivih stvari, kot so avtomobili brez voznikov, kot rezultat inovativnosti globokega učenja.